19 July 2022, Jaap Jumelet with help from co-authors Arabella Sinclair, Willem Zuidema, and Raquel Fernández
Look closely! This Escherian representation directly reflects our priming paradigm!
© Marianne de Heer Kloots

With the rise of extremely large language models such as GPT-3[1] and PaLM[2], and their impressive fluency in generating language, the field of natural language processing (NLP) is increasingly asking which rules of grammar and abstract linguistic classes they have really learned, and, what the right way of finding out the answers to this question even are. In our work, recently published in the Transactions of the Association for Computational Linguistics, we take inspiration from the field of psycholinguistics. This field has studied the same questions about humans, found out how hard it can be to probe for linguistic concepts directly, and developed a variety of useful tools. In particular, ‘priming’ is a key tool in psycholinguistics that turns out to be very useful for our purposes as well.
Priming
Priming, and in particular structural priming, has played a central role in demonstrating experimentally that humans possess abstract knowledge of the structure of sentences. The systematic procedure to study structural priming was introduced by J. Kathryn Bock in her seminal 1986 paper “Syntactic Persistence in Language Production”[3]. Structural priming is a phenomenon in which humans tend to unintentionally repeat syntactic constructions that they have been exposed to earlier. For example, if you let someone read the following sentence (called the prime):
A rock star sold an undercover agent some cocaine.
And next, request that person to describe the following image (called the target):

Then it turns out that they are significantly more likely to describe the target image as “A man is reading a boy a book” (a double-object dative), as opposed to “A man is reading a book to a boy” (a prepositional dative). The reverse would have been true if the initial sentence that we showed would have been “A rock star sold some cocaine to an undercover agent”. We call this phenomenon structural priming: reading the first sentence primed our behaviour on the target task on a structural level.Structural priming is therefore taken as evidence that abstract information, such as the double-object dative in our example, plays an active role in human language processing. Many subsequent studies have examined the various factors that impact this priming behaviour. For example, priming effects increase if the prime and target sentences are more similar to each other, or when the exposure to prime sentences is increased.
Language Models
Language models are trained to predict the next word based on an input prompt. Nowadays these models are large neural networks (often based on the successful Transformer architecture), and trained on billions of sentences. Their success has led to a dramatic paradigm shift within NLP: it has now become standard practice to first pre-train a language model on a large corpus of text, before fine-tuning the model on a more specific task of interest. Language models have become incredibly powerful in recent years, up to the point that they may even fool people into believing, for a while, that they are interacting with a real human being.
In our research, we are interested in approaching language models from a similar point of view as the field of psycholinguistics approaches human language processing. We examine the question of how language models reason about language, and whether they exhibit similar behavioural patterns as humans do. Since we are interested in finding out whether language models encode abstract structural information in their representations, it is a natural step to apply the procedure of structural priming to these models.
Measuring Priming Behaviour
In order to measure structural priming behaviour in language models, we need to make some modifications to our experimental setup. Recall that in the original experiments by Bock (1986) humans were asked to describe an image, after having been exposed to a prime sentence. The language models that we are interested in cannot process images, and can hence only be exposed to text. We instead measure a model’s likelihood of a target sentence directly, conditioned on a prime sentence of a certain structural form. We then compare a model’s likelihood of a target sentence when conditioned on a prime of the same structural form (e.g. active) versus a prime of the opposite form (e.g. passive). This leads to the following definition of the Priming Effect:
PE = logP(targetX | primeX) — logP(targetX | primeY)
Let’s look at a concrete example to see how this is operationalised. For the structural forms X and Y we take the active and passive voice, and targetX will be “The man threw the ball”. The active prime sentence primeX will be “The dog ate the food”, and its passive counterpart then becomes “The food was eaten by the dog”. To compute the model’s likelihoods, we feed the model one type of prime sentence, and conditioned on that sentence we compute the likelihood of the target. The likelihood of the target is computed by feeding the target sentence one word at a time, and computing the probability of the next word. We do the same steps for the other type of prime sentence, and after subtracting the two likelihood scores we obtain the Priming Effect.
Creating an Evaluation Corpus
To evaluate the priming behaviour of a range of language models we create a corpus of template-based prime/target pairs. A major confound that we need to control for when creating this corpus is the overlap between the prime and target sentence. We must avoid that the target is being primed solely because of lexical overlap: if the model only assigns a higher likelihood to the target because the words in the target occurred in the same configuration in the prime we can’t speak of structural priming yet. For structural priming to occur the model must exhibit this behaviour on a more abstract level, i.e. only due to structural overlap the model prefers the target conditioned on the congruent prime sentence.
We therefore construct an evaluation corpus in which we systematically control for the relationship between the prime and target sentences. We create multiple settings where prime and target are completely different except for their structure, and additional versions where we vary the lexical, semantic, and structural similarity. Next to that, we create versions which contain varying numbers of prime sentences to measure whether priming is cumulative (more exposure to a prime results in stronger priming), and versions which vary the distance between prime and target to measure the effect of recency (more recent exposure to a prime results in stronger priming). All combined, this yields a suite of corpora of around 1.3 million prime/target pairs that we call PrimeLM (available here).
Language Models Exhibit Structural Priming
Our experimental setup is divided into two parts: we have a core corpus that we use to measure the general priming behaviour, and specialised corpora that are used to measure various factors related to priming like semantic similarity between prime and target and the cumulativity & recency effects. We evaluate the presence of structural priming using our corpus on a range of language models, focusing in particular on GPT-2.
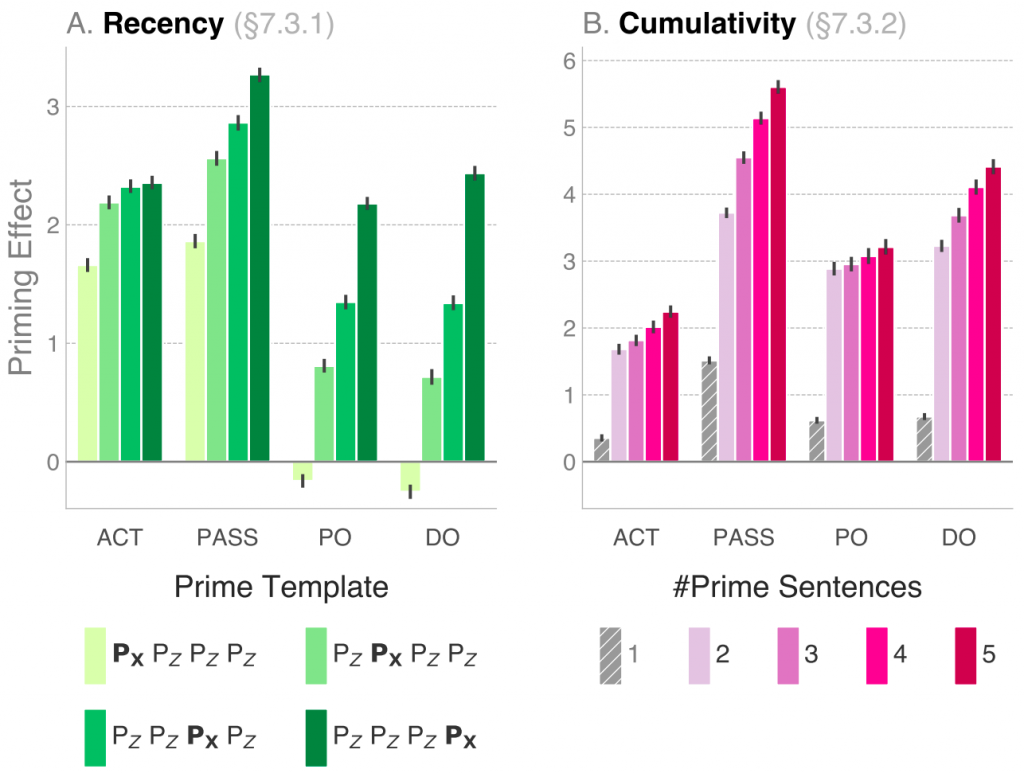
We find evidence that models are susceptible to structural priming, in a manner similar to humans. As an example, we show in the figure above the results of the recency and cumulativity experiments. The left plot shows that the closer a Prime (PX) is to the target (from left to right, right being closest), the stronger the Priming Effect becomes. We increase the distance of the prime and the target by inserting intransitive sentences (PZ) in between. For example, the PX PZ PZ PZ template would translate to a sequence such as:
A king kills a mayor. He can exist. They did go. You will exist.
Followed by a target sentence: The nurse forgot the chicken. The priming effect turns out to be the strongest when the prime is closest to the target sentence (PZ PZ PZ PX).
The right plot shows that the Priming Effect increases proportionally to the number of prime sentences that are fed to the model, before computing the target likelihood. This means that the language models assign a higher likelihood to a target sentence if they have been exposed to several examples of sentences with the same structure (the more the better), even if these earlier sentences have no words or even meanings in common with the target sentence! This provides evidence that the models are truly prone to structural priming: the only information that is repeated between prime and target occurs on a structural level.
Both these effects correspond to human behaviour in priming experiments with recency and cumulativity manipulations.[4][5] Other experiments, related to semantic factors of structural priming and structural complexity, can be found in the paper along with our analysis.
Outlook
Understanding precisely what language models have learnt, and how this influences the language they produce can help us both in understanding how they will perform when used in downstream applications, e.g. identifying possible sources of errors, and in creating more human-like models of language.
One of the main approaches to understanding intelligence is through behavioural studies, e.g. in a given context with a given stimulus, how does the human or AI react? Paradigms from psycholinguistics, which study language processing in humans, can be applied to evaluating the language abilities of language models, testing to what extent they display certain linguistic behaviour in certain contexts, such as the evidence of structural priming in our work. As such, we hope that our study paves a way for a more comprehensive integration of psycholinguistics and NLP.

Machine learning models are often referred to as black boxes. The fields of Interpretability and Explainable AI seek to allow us to ‘look under the hood’ and try to explore the reasoning behind an AI model’s decisions. This can be thought of as parallel to what neuroscientists do when they examine patterns of brain activity and try to relate it to the behaviour of an animal, or to what molecular biologists do when investigating how a particular medicine actually interacts with the biochemistry of an animal cell. More experiments in this area can help to shed light on what linguistic properties are indeed learnt via the language modelling task. This in turn can lead to identifying areas for improvement, and help us understand what is driving the behaviour of these models.
Interested in reading more about this study? You can check out the paper in more detail on arXiv. Do you want to dive directly into the code to see how we implemented our setup in practice? All our scripts and data can be found in this repository.
References
[1] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
[2] Chowdhery, Aakanksha, et al. “Palm: Scaling language modeling with pathways.” arXiv preprint arXiv:2204.02311 (2022).
[3] Bock, J. Kathryn. “Syntactic persistence in language production.” Cognitive Psychology 18 (1986): 355-387.
[4] Kaschak, Michael P. et al. “Structural priming as implicit learning: Cumulative priming effects and individual differences.” Psychonomic Bulletin & Review 18(6) (2011): 1133–1139.
[5] Reitter, David et al. “A computational cognitive model of syntactic priming.” Cognitive Science 35(4) (2011): 587–637.