15 December 2020, Iris Proff

This year, attacks and threats against journalists have increased world-wide, often linked to their reporting on the Corona crisis. The Dutch news broadcaster NOS recently decided to remove its logos from vans to prevent further assaults on reporters. On November 7, Donald Trump declared on Twitter he had won the US presidential election against official reports and millions of US Americans went along with it.
It seems that many people are losing trust in the free press. An important part of the problem is the dangerous spread of conspiracy theories and fake news on social media. Researchers at the ILLC are working on algorithms that can detect fake news and help us understand what characterizes communities vulnerable to misinformation. However, the technical approach to the problem does not come without the danger of unwanted side effects.
What is fake news?
“Fake news” is a fuzzy term. It can refer to anything from accidental false reports by legitimate journalists to political propaganda crafted to manipulate opinion. Click-baiting websites create fake news to maximize advertising revenues. Right wing politicians like to use the term as a generic attack against established media. In all its forms and flavours, fake news has a common effect: it became hard to know who to trust.
Recently, Facebook and Twitter started to take up the responsibility to fight misinformation spread through their platforms. Facebook has introduced a system to slow down the propagation of low-quality content. Twitter started to add warnings to disputed posts by manually selected individuals in the context of the Corona crisis and the US presidential election. The platform does however not make transparent what this selection is based on.
This approach does not scale up. Manually monitoring all Twitter activity for misinformation is not feasible. Why not do it with artificial intelligence instead?
Detecting fake news with AI
Detecting fake news comes down to a typical binary classification problem: you start off with a big database of news items which are labeled as real or as fake. Typically, these datasets do not specify what type of fake news they contain. Then you train a neural network to distinguish between the two types of news. After training, you can input a news item your model has not yet seen and out comes the model’s classification: real or fake. There have been many attempts in recent years to detect fake news that follow this approach.
With few exceptions, these models do not fact-check. A neural network does not know who won the US election or how a Corona vaccine works. Instead, it learns general properties of fake news items, such as their structure, writing style and topics covered.
Some approaches to fake news detection additionally consider the social media users that tend to spread them. What jobs do they have? Political orientation? Where do they live? Using such information is effective but problematic. It allows the model to build explicit user profiles and to determine which political affiliation, religion, age, or jobs are associated with spreading fake news. This opens the door to bias and discrimination.
Two recent research projects by scientists at the ILLC focused on overcoming this problem.
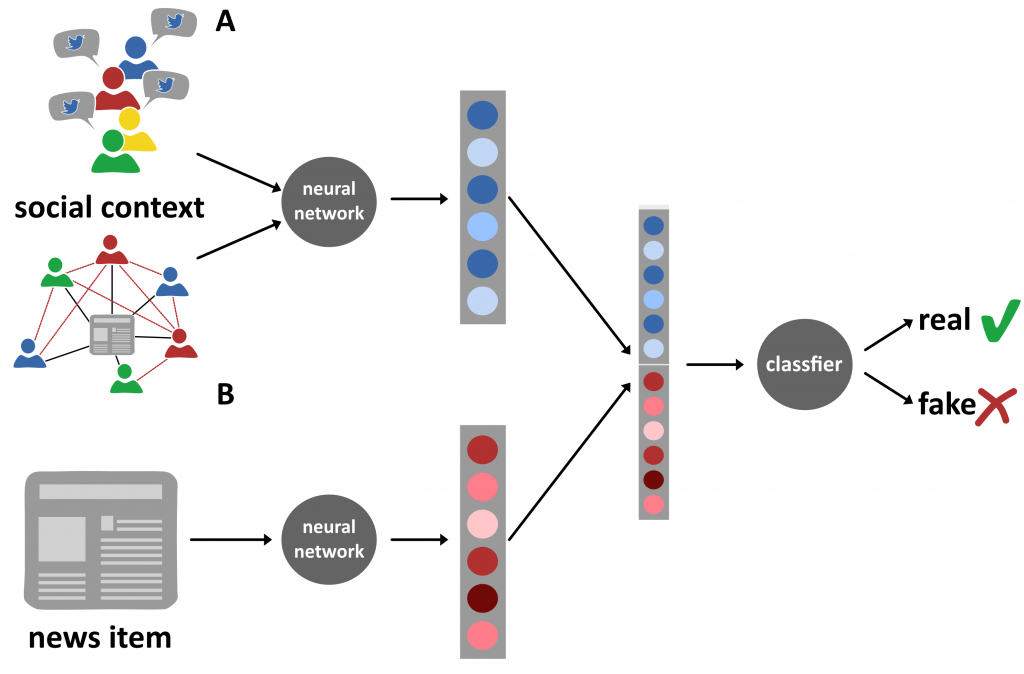
Social networks reveal fake news spreaders

“We believe that user communities on social media hold more valuable information than individual users”, says Shantanu Chandra, who completed a research project on fake news detection for his master’s thesis in Artificial Intelligence. On social media, people with similar interests form implicit communities – so called echo chambers – and share similar content. An individual’s view is thus echoed and reinforced by their social network.
Shantanu built a model that makes use of the echo-chamber effect. One side of the model considers the text and title of a news item. The other side is a graph neural network handling information about the users that shared the article: what type of content do they usually share? And how are they connected with each other?
Incorporating social network information, the model can identify fake news more accurately. On a dataset containing news about celebrities, Shantanu’s model performs better than any other on this data thus far. Along the way, he made an interesting observation: most users share both fake and real news, but some exclusively spread fake news. The more ‘fake-news-only’ users there are, it seems, the easier it is for the model to pick out fake news items. Those users were unlikely to be social bots, as these were identified and excluded during the creation of the dataset.
The language of fake news spreaders

Marco Del Tredici developed another approach to detect fake news by looking at the language users produce themselves. “No language is produced out of a social context”, the researcher states. “If you add extra information about the speaker and context, you have a better chance to understand what they mean.”
Marco’s research rests on two assumptions drawn from sociolinguistic research: first, people who are more prone to spread fake news share a specific set of thoughts and ideas. Second, these thoughts and ideas are reflected in language.
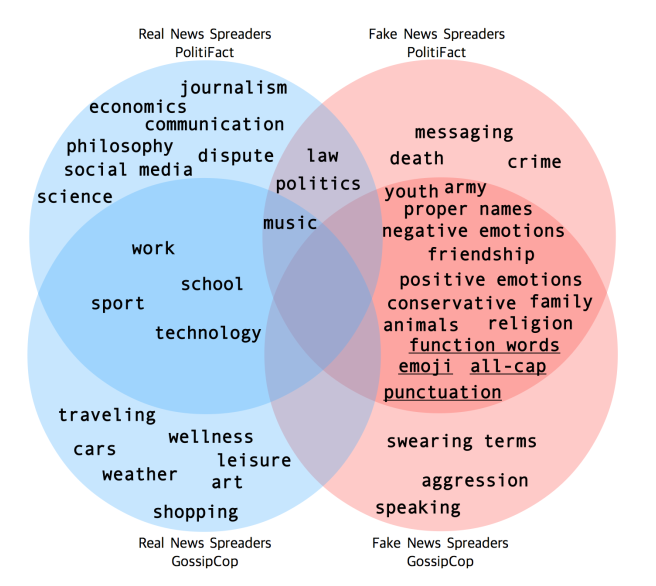
If the language of ‘fake news spreaders’ really has specific features, what are those? To find out, Marco used two convolutional neural networks, which he trained on the text of the news items and on the language that users generated themselves on Twitter. Convolutional neural networks are not commonly used in the field of natural language processing, as they do not capture the order of words. But they have an advantage: they seem to make it easier than other network architectures to look behind the scenes and find out what the model bases its decision on.
Marco found that using users’ previous tweets improves how well the model can detect fake news. “Fake news spreaders have a language that is very consistent across datasets, reflected both in the topic and style”, he concludes from his analyses. People who spread fake news tend to talk about specific topics such as war, crime and violence, but also about family, emotions and religion – no matter if they share articles about celebrities or politics. They also tend to use specific emojis and punctuation, all caps words and first-person language. Users who share real news, on the other hand, mostly talk about topics associated with the articles they share.
In a nutshell: state-of-the-art neural networks can detect fake news with fairly high accuracy, especially when they consider the social context in which news items spread. They can also reveal what characterizes communities vulnerable to fake news. But how to use these models in the wild?
Fake news detection in the wild
Let’s assume Twitter had an algorithm at hand that almost perfectly picks out fake news items. The most radical strategy would be to delete all posts containing news items that the algorithm classifies as fake. However, this would lead to the removal of some items that are not actually fake news, as no algorithm will work at 100 % accuracy. With the ability to censor social media posts comes an enormous power that could easily be questioned and misused. Freedom of speech – a value Twitter strongly identifies with – would be at stake.
A more reasonable option might be to flag news items with a warning, similar to the strategy Twitter is pursuing already manually. However, Twitter currently provides an explanation for why a tweet is disputed. This is well beyond what today’s fake news detection algorithms can do. The effectiveness of flagging social media posts with generic warnings remains unclear. It might increase trust in social networks but could also achieve the opposite and antagonize online communities even more.
A solution could be to keep humans in the loop: an algorithm picks out posts that likely contain fake news, which are then checked by a human can add explanations. Manpower is a bottleneck here, but it might be a good strategy to pick out misinformation about specific events or topics, such as elections.
Another challenge is the algorithms’ ignorance of the intentions behind fake news items. Should we treat malicious political manipulation the same as false but harmless click-baiting news? A one-fits-all solution to deal with everything that falls under the ill-defined term “fake news” probably does not exist.
When algorithms discriminate
Finally, there remains the threat of discrimination that lurks behind many AI applications. For instance, many hiring algorithms show implicit gender biases. Ads for supermarket cashier positions are mostly shown to women, while men are more likely to see ads for higher-paying jobs – even if the underlying algorithm had no explicit knowledge of gender.
Similarly, even if you do not feed users’ political affiliation into your fake news detector, it might still pick up on it by looking at the language users produce and the content they share. Your model might classify an item someone shared as fake, just because this user fits the profile of the classical ‘fake news spreader’. In other words, the errors your model makes will affect certain communities more than others – an effect known as disparate impact.
“We need to avoid stigmatizing people”, emphasizes Raquel Fernández, researcher in natural language processing at the ILLC. Given that neural networks run on statistical generalizations, this is not a trivial task. In the end, the technical solution to the threat of fake news is only half a solution.